🗓️ 일정
2차 미니프로젝트: 3/18 ~ 3/20

❓KT에이블스쿨 미니프로젝트란?
미니 프로젝트는 이론, 실습 강의가 끝난 후 배운 강의를 토대로 실제 사례에 적용해보는 시간이다. 해결해야 할 미션, 데이터, 도메인 정보, 가이드가 제공되면 개별 실습을 통해 스스로 문제를 해결한 후, 조별 실습을 통해 공동과제를 수행한다. 그리고 전체 발표 시간을 가져 다양한 솔루션을 공유한다.
📑 1일차
❗주제 및 미션
두 번째 2차 미니 프로젝트 주제는 서울 지역의 2022, 2023년도 미세먼지 데이터와 날씨 데이터를 활용하여 미세먼지 예측에 관련 있는 데이터 항목으로 데이터를 구성 및 전처리를 진행하여 1시간 후 미세먼지 농도를 예측하는 머신러닝 모델 구현하는 것이다.
💡도메인 이해
도메인 이해를 위해서 현재 환경부에서 어떻게 미세먼지 농도를 예보하고 등급을 나누고 있는지 살펴보았다.
또한, 미세먼지 농도 예측이 필요한 이유를 미세먼지가 우리에게 미치는 영향, 예측을 통한 대비로 유용한 점 등을 새롭게 알게되었다. 제공된 데이터에서 증기압, 이슬점 온도 등 모르는 단어들의 뜻도 살펴보면서 어떤 기후 변수가 미세먼지 농도에 영향을 미치게 될지 예상해보기도 하였다.
📊데이터 분석 및 전처리
우선 미세먼지 데이터에서 지역, 주소 등 날씨와 관련 없는 변수는 삭제해주었다. 그리고 결측치를 확인했는데 결측치가 모든 변수가 80이상이었다. 이를 모두 0으로 처리하지 않고, 선형보간법을 이용하여 처리해주었다. 그리고 각 변수들의 기초통계량, 분포를 그래프와 표를 통해 확인하였다.
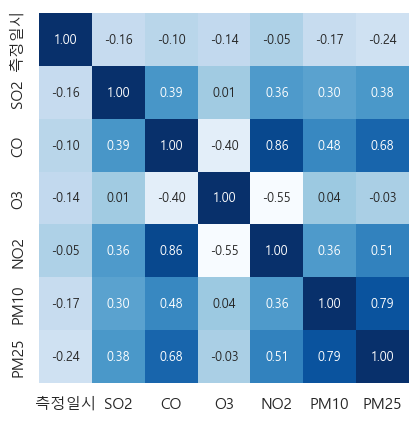
그리고 미세먼지 데이터와 날씨데이터를 측정시간 기준으로 합쳐주고, 전처리를 이어서 진행하였다.
합쳐진 새로운 데이터프레임에서도 날씨 변수들 중에서 QC플래그 등 팀원들과 상의하여 미세먼지에 영향을 미치지 않을 것 같은 변수들과, 미세먼지 예측과 상관 없는 측정명 코드 등의 변수들을 삭제해주었다.
날씨 데이터에서도 결측치가 많은 변수들을 대부분 선형보간법으로 처리해주었고, 강수량 변수만 0으로 처리하였다.
강수량이 NaN이라는 것은 비가 안 왔다고 판단하여 0으로 처리해도 괜찮을 것 같다고 판단하였다.
그리고 한 시간 후의 미세먼지 농도를 측정하기 위해 종속 변수로 새로운 열을 만들어 추가하였다.
종속변수를 만들 때는 1시간 후인 현재 시간인 t에서 1을 더해준 t+1일 때의 미세먼지 농도 값 만들어줘야 한다.
따라서 기존에 있던 현재 시간인 t일 때의 미세먼지 농도 값에서 .shift(-1)을 사용해서 행을 하나씩 위로 당겨주었다.
그러면 맨 마지막 행은 1시간 후의 미세먼지 농도 값이 없으므로 NaN값이 발생한다. 이는 바로 위의 행의 값으로 대체해주었다.
# 1시간 후의 미세먼지 농도 값(종속변수)를 만들기 위해 행을 위로 한 칸씩 올려준다.
df_23['PM10_1'] = df_23['PM10'].shift(-1)
# 맨 마지막 값은 이전 값으로 채워준다.
df_23['PM10_1'] = df_23['PM10_1'].fillna(method='ffill')마지막으로 모델링을 위해 학습데이터, 검증데이터를 나누었다.
train_x = df_22.drop(target, axis=1)
train_y = df_22.loc[:, target]
test_x = df_23.drop(target, axis=1)
test_y = df_23.loc[:, target]
🚀 모델링
모델링은 LinearRegression, RandomForest, GradientBoosting, KNN을 돌렸다.
이때 모델링을 돌리면서 변수 중요도를 체크해봤는데 아무래도 1시간 전의 미세먼지 농도, 초미세먼지 농도가 영향을 많이 미치는 것을 확인하였다. 그래서 독립변수 x에서 이 둘을 제거하고 다시 돌리기로 하였다.
다시 돌린 결과, 대부분 모델에서 1시간 전의 일산화탄소 농도, 시정(10m), 습도가 1시간 후의 미세먼지 농도를 예측하는데 중요한 변수로 나왔다. (시정(10m)이란? 10m앞에 대기 중의 먼지, 스모그, 안개 등으로 인해 시야가 가려진 정도)

그리고 각 모델을 MSE, R-squared Score로 평가하였다.
모델 성능평가로 비교한 결과, 그라디언트 부스팅의 예측 성능이 가장 좋았고, KNN의 경우 다른 모델에 비해 이상치를 잘 예측하는 것을 확인하였다.
- 그라디언트 부스팅 성능평가: MSE 617.869 / R2 0.449
- KNN 성능평가: MSE 761.989 / R2 0.318


📑 2일차
❗주제 및 미션
1일차에 미세먼지 농도 예측이라는 미션을 완료하고, 2일차에는 새로운 미션이 주어졌다.
두 번째 미션은 장애인 콜택시를 이용하는 고객들의 불편사항을 개선하고 서비스의 품질을 높이기 위해 콜택시 운행이 종료된 시점에 다음 날의 기상 예보를 바탕으로 기상 상황에 따른 장애인 콜택시의 평균 대기 시간을 예측하고 예상 대기 시간을 제공할 수 있는 모델을 완성하는 것이다.
2일차에는 모델링 전에 데이터 전처리 및 분석을 진행하였다.
💡도메인 이해
우선, 장애인 콜택시 운영 체계를 살펴보았다. 그리고 장애인 콜택시를 이용하면서 어떤 부분에서 가장 불편함을 느끼는지 살펴보았는데 너무 긴 대기시간이었다. 이어 시간대별 대기시간 현황을 확인하였고, 개선시급도 분석 결과 대기시간이 가장 시급하게 개선해야 할 항목으로 도출되었다는 것을 확인하였다.
도메인 이해를 통해 비장애인으로써 장애인의 입장에서 장애인 콜택시의 예상 대기 시간을 제공하는 서비스의 필요성을 이해할 수 있었다.
📊데이터 분석 및 전처리
택시운영 데이터에서 접수건, 탑승건, 대기시간 등의 각 변수들을 주기별 분석을 위해 년도, 월, 주, 요일 날짜 변수를 추가했다. 그리고 모든 변수들을 주기별로 기초통계량을 확인하고, Histogram, Boxplot, Barplot 등으로 시각화하여 변수를 탐색하였다.


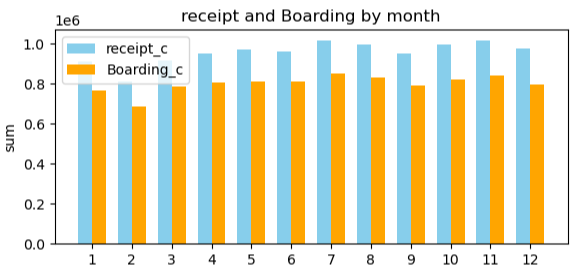

그 다음, 모델링을 진행하기 위해 새로운 데이터프레임을 만들었다.
날씨 데이터와 택시 운행 정보 데이터를 합치고, 년, 월, 요일, 일 날짜 변수와 추가로 공휴일 변수, 일주일간 평균대기 시간, 탑승률을 새로운 변수로 추가하였다.
파이썬에 나라별 공휴일 정보를 제공해주는 라이브러리를 이용해 공휴일 변수를 추가하였다. 그리고 휴무일이지만 라이브러리에 없는 휴무일은 직접 추가하였다. 따라서 휴무일이면 1, 아니면 0으로 변수를 생성하였다.
# 휴무일 데이터 패키지 설치
!pip install workalendar
# 2023년 대한민국 휴무일 데이터프레임 생성
from workalendar.asia import SouthKorea
cal = SouthKorea()
pd.DataFrame(cal.holidays(2023))
일주일간 평균 대기 시간은 .rolling.mean()을 사용하여 추가해주었다.
# 일주일간 평균대기시간 변수 추가
df['wt_ma7'] = df['waiting_time'].rolling( 7, min_periods = 1).mean()탑승률은 탑승건을 접수건으로 나눠 추가해주었다.
df['board_ratio'] = df['boarding_c'] / df['receipt_c']새롭게 만들어진 데이터프레임에서 날짜 변수와 새로 추가된 변수에 대한 앞서 변수 분석에서 진행한 방법과 같이 단변량 분석을 진행하였다. 각 변수에 대한 단변량 분석을 마치고, 독립변수와 종속변수(대기시간)을 비교 분석하였다. 비교 분석할 때는 숫자형 변수와 범주형 변수를 나눠 다양한 시각화 분석을 진행하였다.
전체적으로 변수들 간의 관계는 heatmap을 통해 확인하였다.
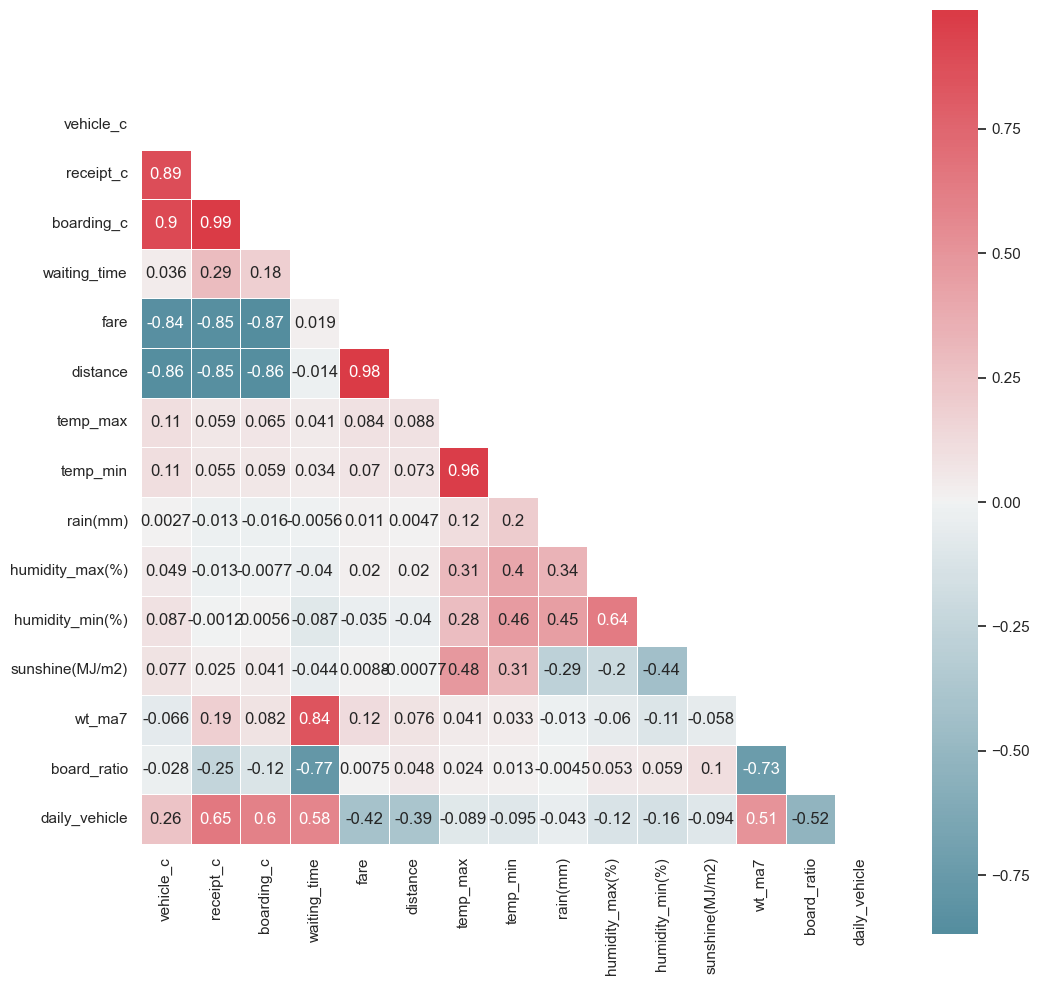
최종적으로 t-test와 anova 통해 수치화도 진행하여 종속변수와 강한 상관관계를 가지는 변수, 약한 상관관계를 가지는 변수, 관계가 거의 없는 변수로 다음과 같이 정리하였다.
- 강한 상관관계를 가지는 변수 - 탑승률, 휴무일, 요일, 일주일간 대기시간
- 약한 상관관계를 가지는 변수 - 접수건, 탑승건
- 관계가 거의 없는 변수 - 날씨 변수들
데이터 전처리 및 분석을 하고 시간이 조금 남아 더 추가할만한 변수가 있는지 팀원들과 논의 후 장애인콜택시와 관련된 자료를 같이 찾아보았다. 따라서 코로나 유무, 강한 비, 계절 등 더 추가하여 분석해보았다.
📑 3일차
❗주제 및 미션
마지막 날 3일차에는 2일차에 이어서 장애인 콜택시 대기 시간을 예측하는 모델을 만들고, 성능평가를 진행하였다.
🚀 모델링
모델링을 정말 다양하게 진행해보았다. 그리고 실제값과 예측값에 대한 그래프 시각화를 통해 하나씩 확인해보았다.
성능 평가는 MAE(Mean Absolute Error), MAPE(Mean Abolute Percentage Error), R2-Score를 통해 평가하였다.



🔑 결론
모델링을 다 하고 인사이트를 분석한 결과는 다음과 같다.
[논의사항]
1) 차량운행 수가 어느 월에 가장 많은지
- 11월이 대채로 많으며 (가을에 분포되어있다. 공휴일이 없기 때문에 차량운행 수가 많을 것이다.)
- 공휴일이 없는 월 : 7월, 11월(공휴일x - 248/240건)
2) 하루에 처리해야할 접수건수(파생변수: 접수건/차량운행수)가 가을에 왜 낮은지
- r = 0.58 (한 차량당 처리해야할 건수가 많기 때문에, 평균대기시간이 길것이다.)
- 9월달이 가장 차량건수가 적고, 모든 해가 그렇진 않다.
3) 다른 교통수단에 따른 택시 접수율도 확인에 볼 필요도 있음. (4번)
- 공휴일에 타 대중교통 운행이 적어지기 떄문에 택시타는 비율이 많아질 것이다.
4) 차량운행 값이 왜 매일마다 다른지
- 차가 밀리는지 안밀리는지 따라 달라질 수 있다. (7km 반경이 넘어가면, 대기번호가 밀려 접수건수가 높아도 탑승건수가 적을것이다.)
5) 한해의 차량 평균대기시간이 12월에 도달할수록 커지는지
- 운행횟수 대비 접수건이 많아져서 증가하는 양상을 보임.
6) 평균 대기시간이 이상치에 해당하는 경우에 어떤 특징이 있는지
- 4)항목과 동일하게 접수건에 영향을 많이 받있을 것이다.
[추가 인사이트]
- 탑승률이 주말에 낮은 이유 : 병원, 복지관을 평일에 가는 것이 영향이 있을 수 있다고 판단함.
- 2020년도 코로나로 인해 차량운행수, 접수건, 운행건이 줄다가 23년 이후로 증가함.
- 장애인콜택시에 대한 운행 대수 증가 등의 정책 변경으로 2020년도 차량운행수 증가함.
- 주말에는 이동거리가 늘어나서 비용이 올라감.
- 가을의 평균대기시간이 길다. (공휴일이 가장 많고, 공휴일의 타 대중교통 운행이 적어지기 때문에 택시타는 비율이 많아질 것이다.)
- 습도가 높을때, 택시 탑승률이 높다.
- 강수량과의 택시운행데이터 통계분석 시 접수건과 가장 유의미하였다.
💭2차 미니프로젝트를 마치고
장애인 이동건 보장을 위해 자주 시위를 하는 뉴스기사를 자주 접하면서 장애인 대중교통 이용 개선에 대해 관심이 있었어서 그런지 프로젝트를 진행하는 동안 재미있었다. 그리고 데이터를 분석하고 모델링을 돌리는 것에서 마무리 하는 것이 아닌 결과가 나온 원인에 대해 찾아보면서 문제 해결에 대한 접근 방향을 더 명확하게 할 수 있었다. 혼자 수업을 듣고 개인 실습을 했을 때 너무 어려웠어서 미니 프로젝트가 걱정했었는데, 팀원들과 함께 프로젝트를 진행하면서 머신러닝에 대한 이해가 더 확실히 되었다는 것이 느껴졌던 2차 미니프로젝트였다.

'🚩 대외활동 > KT 에이블스쿨' 카테고리의 다른 글
| [KT AIVLE School] KT에이블스쿨 5기 - 4차 미니프로젝트 (0) | 2024.05.24 |
|---|---|
| [KT AIVLE School] KT에이블스쿨 5기 - 3차 미니프로젝트 (0) | 2024.05.14 |
| [KT AIVLE School] KT에이블스쿨 5기 - 1차 미니 프로젝트 (0) | 2024.04.04 |
| [KT AIVLE School] KT에이블스쿨 5기 수도권 AI 최종합격(준비과정) (4) | 2024.02.02 |